
This week while I am producing more XML files for the five directors, I am trying to design a mechanism to showcase how flexible and transformable XML files could be. My first trial is about XML-XSLT-HTML, which means I use XSLT (Extensible Stylesheet Language Transformations) to transfer my XML code into HTML for web content.
XML: https://drive.google.com/file/d/1GrrzZob4bq5U9sFbLRZ1OTTojxi2N2BY/view?usp=share_link
XSLT: https://drive.google.com/file/d/1V97Dj4S4TNtniGOmGAp3WrxePm-GtIZi/view?usp=share_link
And here is the screenshot of my result.
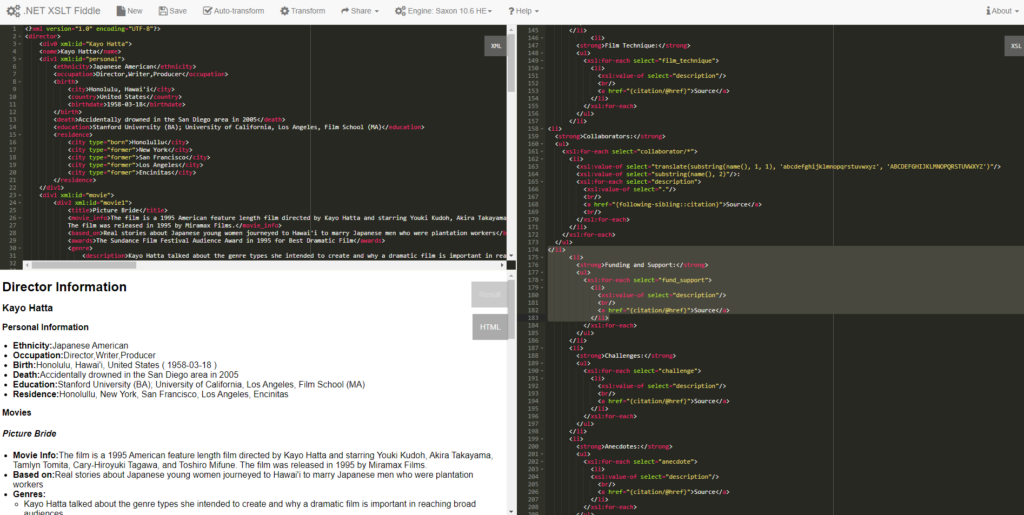
As you can see in my XML file (upper left), I have adjusted the structure in XSLT five times to get the current result (button left). So then, I will ask members to revisit their structures and give me the files. I will guide everybody through the DTD and XSLT tomorrow; ideally, we will get three pilot samples that we could show on our website. A total of 15 XML files will be saved in our shared folder. We decided to do 3 pilot example HTML pages, and instead of only showing the final result, we will tell the behind-the-scenes story with screenshots or screen recordings of our codes. The time probably wouldn’t allow us to do all 15 in this XML-XSLT-HTML format, but if anyone follows our workflow, they could get an HTML code by spending some time and effort.
Designing our DTDs and XSLT is difficult because we encoded our files individually. It is just so hard to do collective encoding this semester due to time limits and course structure. We don’t have a mechanism like the Orlando project, so we tried our best to give pilots and show our workflow.
You might notice that we use different tags, and even for one director, for different films, some tags appear, and some do not. (Because for some films, we just couldn’t find that much information). So, in this case, we need to give a conditional code in XSLT as xsl: if to make sure there is no empty content in our display. This if logic also works in our DTDs in which a question mark appears after the element like this “<!ELEMENT div2 (title, movie_info, based_on?)>”, indicating that the element is optional (it can be present once or not at all).
So to give a bigger picture, I will mention that we collect the data, choose annotation tools as pointers, and write the XML code in my presentation. While we give an example of XML-XSLT-HTML, there are also possible options for JSON, CSV, SQL database, or mobile applications. And you may wonder about the relationship between XML and TEI; this is my work this week before the final delivery to explain the connection between XML-TEI. Actually, the Orlando team started with the SGML and transferred their codes to the TEI structure, which I guess is for publication purposes.
Something you might read further: (as a quick answer to why we are building XML files on women directors by our scholarly annotations instead of scraping data directly from the internet)
I tested a way to retrieve XML information of Kayo Hatta using Google Colab from IMDB:
https://colab.research.google.com/drive/1ltiKClrJCG9-MSmFXA6fLKgkO0dTMpki?usp=share_link
Look at the result and how limited and short it is:
